
ADAPT: Applying Enterprise AI Architecture to the Digital Lab

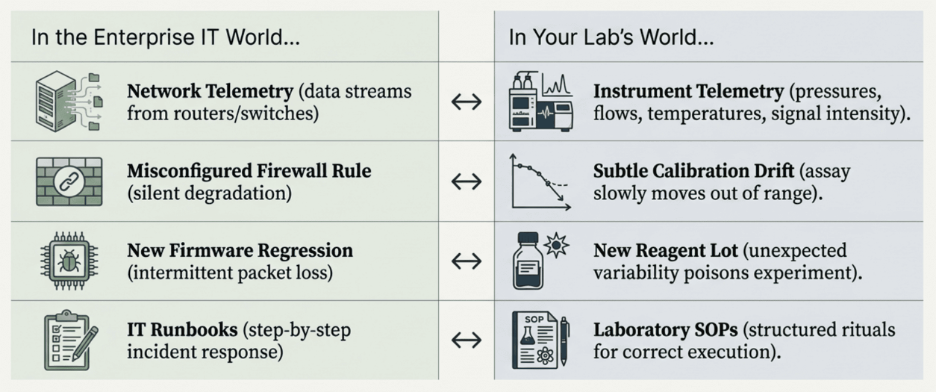
Modern laboratories have evolved into cyber-physical systems. Telemetry streams from instruments. Years of structured data reside within LIMS and ELN platforms. Environmental sensors monitor temperature, humidity, and vibration. Robotics automates sample handling. Cloud services connect multi-site operations. AI tools now begin generating interpretations.
The complexity curve has outpaced individuals’ ability to synthesize it all. Senior scientists who “just know” how everything relates to one another cannot possibly retain all the telemetry, historical data, and operational conditions in their minds. According to W. Edwards Deming, “a bad system will beat a good person every time.”
We are now facing what I call the digital scavenger hunt. A QC run has failed. Scientists spread out across tools to determine the issue; one investigates the ELN, another reviews log entries from the instrument(s) involved, someone else searches past service requests, while the last attempts to recall whether the problem occurred three years prior. All of this is a reactive process. The learnings from the event remain trapped in people’s minds, scattered documents, and hallway conversations.
This article will describe ADAPT (Adaptive Digital Automation and Proactive Transparency), a framework developed from the deployment of multi-agent AI systems at enterprise scale. It will explore how the same architectural patterns apply directly to connected laboratory environments. The central premise, which I presented at Technology Networks’ “Automation and AI: Building the Digital Lab” symposium, is simple: the structural challenges experienced in enterprise IT and digital labs are identical. Only the nouns differ.
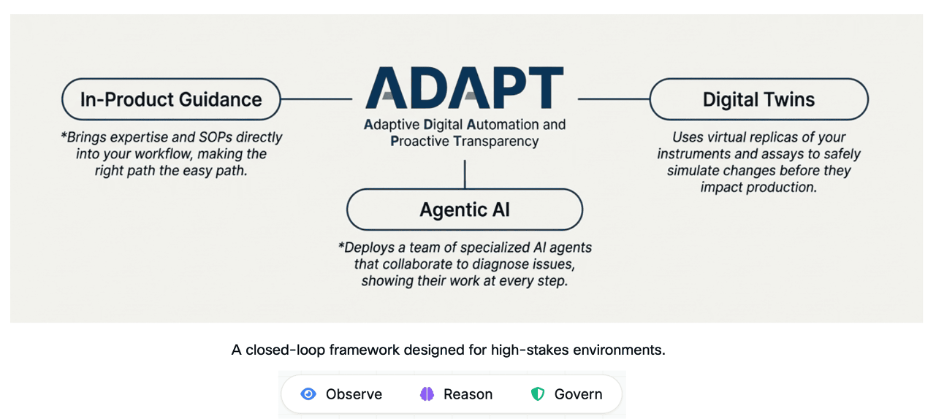
Three Pillars for Humane Automation
ADAPT combines three capabilities: in-product guidance, agentic AI, and digital twin governance. All three function in a closed loop: observe, reason, guide, simulate, then act. The key term here is “humane.” The goal is not to develop the most automated laboratory. It is to develop the most trustworthy laboratory.
In-product guidance transforms software from a passive entity into an active coach. Rather than relying solely upon thick manuals or independent knowledge bases, it is integrated directly into the LIMS or instrument portal. Thus, in-product guidance meets the user where they are, in context, at the precise moment of need, with the combined intelligence of human and AI-leveraged insights.
An example of in-product guidance is displaying a banner indicating that calibration is due for instrument HPLC-002 before the next batch is processed, as soon as the scientist logs into the LIMS. Rather than relying on memory or a paper calendar, the system presents the reminder at login and allows the researcher to access the calibration workflow immediately. While setting up assays, the interface displays potential issues such as: “Reagent lot 7B has a known deviation.” While reviewing QC results, the interface identifies patterns that indicate: “This drift pattern appears similar to a previously identified incident related to Column D-22.”
An important aspect of the paradigmatic shift is that in-product guidance does not remove the researcher’s judgment. Instead, in-product guidance reduces the cognitive burden of finding the right information at the right time. Our experience deploying digital adoption platforms at the enterprise level demonstrates that integrating guidance directly into the product (rather than placing it in separate manuals) significantly reduces onboarding time, reduces configuration errors, and improves process consistency for teams.
Agentic AI deploys a team of specialized agents that collaborate to diagnose issues transparently. Traditional AI acts as a smart but inexperienced intern: excellent at summarizing, but prone to missing cross-domain relationships in high-stakes situations. On the other hand, Agentic AI acts as a well-experienced, skilled troubleshooting team, with each agent possessing deep knowledge in one domain and cross-checking one another’s recommendations before furnishing conclusions.
In a digital lab environment, an out-of-specification QC result triggers simultaneous investigations across multiple agents. The Instrument Agent evaluates telemetry, error messages, and pressure traces. The Reagent Agent reviews lot numbers, expiration dates, and vendor advisories. The Environment Agent evaluates the relationship between performance and historical data collected from temperature, humidity, and vibration sensors. The Workflow Agent reviews the run timing and sequence versus standard operating procedures (SOPs) and historical trends.
Each agent provides its own perspective. For example, the Instrument Agent may flag a pressure pattern that matches partial column clogging. The Reagent Agent may identify that failures are correlated to a particular reagent lot. The Environment Agent may detect that incidents occur during periods of elevated room temperature. Collectively, they present a composite view of the possible causes that could have taken hours to recreate manually.
The output is a structured explanation, not a black-box conclusion. The system may report: “Most likely root cause: partial column clog (high confidence). Reagent aging is a secondary factor (moderate confidence). Supporting evidence is provided below.” The scientist can accept, question, or overrule the recommendation, but will no longer wonder why it was provided. Every inferential link within ADAPT is traceable and auditable, and is directly linked to the original data.
This is important for regulated environments. “Because the model said so” is not an acceptable answer in a GLP, GMP, or CAP-accredited laboratory. Therefore, every recommendation produced by ADAPT must be explainable, and the reasoning chain is stored as an immutable record. Think of it as a transition from “AI as oracle” to “AI as expert witness”, where AI is always prepared to support its reasoning with evidence.
Digital twins provide a safe harbor for experimentation. Before applying a protocol modification, a QC threshold adjustment, or a firmware upgrade, the proposed change is simulated within a virtual replica constructed from the laboratory’s own historical data.
For example, consider a laboratory with three years of QC data for a particular assay. The research team is considering tightening the assay’s tolerance limits. Rather than relying on intuition, the digital twin simulates historical data using the new rule and reports: “This change will increase failure rates by 18%, but will also capture three previously missed drifts.” The scientist can then make an evidence-backed decision, and the simulation report becomes part of the change-control documentation.
Firmware upgrades represent another significant application. Anyone who has gone through a firmware upgrade that inadvertently changed instrument behavior understands how difficult it can be to diagnose afterward. Using a digital twin, the proposed firmware upgrade is applied only to the virtual replica, and performance metrics are compared before and after the upgrade using historical run data. If any concerns arise, the implementation is halted. If benefits arise, the team can proceed with greater confidence and documentation.
The Closed Loop
The three pillars of ADAPT are interconnected into a single closed loop. Agentic AI uses telemetry, QC results, and workflow data to create explanations and propose modifications. In-product guidance takes those explanations and creates step-by-step workflows, proactive alerts, and contextual cues. Digital twins allow the team to simulate proposed changes before exposing real samples and instruments. Only after the team has reasoned, guided, and simulated does it implement the change in the actual system. And each change is documented.
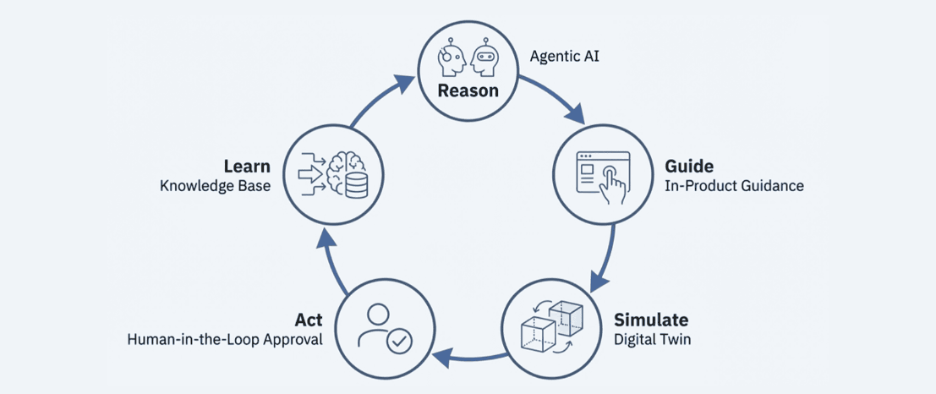
Learning outcomes flow back into the loop. If a guided change reduces failures, that information enhances the model. If a recommendation is consistently rejected, that suggests the logic or data requires correction. Over time, ADAPT enables laboratories to evolve from reactive firefighting to proactive and explainable optimization.
What We Learned
Four lessons from implementing these patterns at enterprise scale apply directly to digital lab environments.
First, users trusted the system more when it acknowledged uncertainty. Initially, we hesitated to present uncertainty. Users actually improved their own judgment when the system indicated uncertainty.
Second, the experience layer had a much greater impact on adoption than the model’s quality. Early deployments that connected AI directly to automation without an experience layer resulted in very little adoption. Users were disinclined to grant automation permissions because they were unaware of the implications. When we made the reasoning behind agent activity visible, the trajectory of adoption shifted.
Third, the involvement of humans in the loop was a feature, not a safety net. Users wanted to maintain the ability to participate in the loop even for routine activities. The approval phase provided users with an opportunity to build their own intuition for when to trust the system.
Fourth, the orchestration layer became the focus of security. The component that directs task assignment between agents aggregates context, delegates credentials, and controls routing. This layer should be subject to the same level of scrutiny for security risks as any other critical infrastructure.
Where to Start
My advice is practical: get started with a limited set of workflows, establish its value and trustworthiness, and then expand. Select one process with a high-impact workflow, such as calibration for a critical instrument or QC review of the most expensive assay. First, implement in-product guidance in that process. Assess error reductions, training times, and user satisfaction. Next, deploy agentic analysis for a limited subset of repetitive QC anomalies. Finally, deploy a digital twin for a single type of change. After demonstrating value and trustworthiness at a small scale, you will have sufficient data, anecdotal examples, and trust to expand.
The AI-powered lab of the future will not be defined by how many decisions it makes on its own. It will be defined by the clarity it gives to the humans who remain accountable.
Resources:
- Try out the live simulation here: https://adapt-lab.vercel.app/
- Github Code below






